Type-safe stream processing in TypeScript
This post contains a lot of back-story about how this all came about, you can skip ahead if you only care about the code.
In case you haven't worked with TypeScript before: TypeScript is a superset of JavaScript that enhances the language by providing optional static typing. It's designed to scale well in large code-bases. I've been working on a TypeScript based application (frontend and backend) for the last 9 months and I have to say, I'm not at all disappointed. In fact, I'm quite impressed.
The type-system additions to JavaScript make it easier to navigate your code, giving you more confidence during refactoring, and making it infinitely easier to comprehend a system. Especially the last part is super important for me. I work a lot in multi-team projects. For the team to be able to understand a system is the single most important thing for me.
A Transformation
In order to better understand what I'll be demonstrating I'll give you a little background information. When I joined the team the project was about 2 years in development. The MVP period was finished and the product had proven itself worthy of further investment. Adoption was increasing within the organisation and there was talk of making the product a mission critical application.
The product is a real-time dashboard application. It processes many data-streams available within the organisation. The dashboard allows users to pro-actively engage with their operational activities.
All the views in the dashboard are highly specialised and meticulously designed. Each view was provided with data which it accumulated over time. Initially the views were simple, over time they grew in size and complexity. Some grew so large that the state needed for an initial render (represented in JSON) clocked in at around 16MB.
The processing part of the platform, projecting streams of data into read models, had some limitations. It could only store JSON blobs on disk, these blobs had a size limit of 16MB. We often had to arbitrarily limit the use-case to stay within that 16MB magical limit.
While this limit was configurable it was strongly advised not to increase this since flushing big blobs to disk causes a significant performance penalty. The limiting of this data was not easy; it resulted in trial-and-error and a lot of guesswork. This was simply not acceptable for a product that was on route to become mission critical.
The documentation around the solution was mostly lacking or out of date. Developers were often left with no other option than to dig through a mailing list with 6 year old posts containing code snippets.
On top of all that, the product, a functional database for event-sourcing, had severe stability issues. It required a nightly reset, removing all the data. We ended up having to require our data providers to create bulk-restore mechanisms to recover from catastrophic data loss. So yes, you read that correctly, the database's instability forced us to suffer from catastrophic data loss every night. It was a pain to have in production. And while we thought we had it bad, companies around us were sometimes resetting this database up to 3 times A DAY.
Needless to say, we decided that moving away from the current solution was the right option. We needed something better. After some research and experimentation we began developing our own stream processing application using Kafka and TypeScript.
The requirements
The system needed to be able to process multiple streams of data. Each stream would contain one or more types of messages. These streams would be consumed, resulting in newly dispatched data (events) and/or state accumulation (read models).
In order for the dashboard (web application) to show the data, in real-time, the initial state is fetched via a REST call. Subsequent updates are received over a WebSocket. In the middle of this all are projections. The projections are responsible for handling the data in the streams. A big part of the developer's work is ensuring all the data from a given stream is handled.
The problem
In the process of creating a new foundation we wanted to make sure we had extensive type-safety. This is important because:
- Correctness of data is important to the project.
- Data is re-used all over the place.
- Data types give developers better mileage out of their IDE's.
This was especially important on the consumer side. When consuming multiple types of messages over a stream we needed to be able to distinguish message handlers for each given type.
A basic shape of a message was:
interface Message<T> {
type: MessageType; // enum
payload: T;
}
From a developer experience point of view the following interface would be very nice to use:
// the important stuff
consume(Topic.TOPIC_NAME, {
[MessageType.GateChange]: async (payload: GateChange) => {
// handle payload
},
[MessageType.FlightUpdate]: async (payload: FlightInformation) => {
// handle payload
}
});
// less important stuff
enum MessageType {
GateChange = 'GateChange',
FlightUpdate = 'FlightUpdate',
}
interface GateChange {
FlightIdentifier: uuid,
PreviousGate: string,
CurrentGate: string,
}
interface FlightInformation {
FlightIdentifier: uuid,
Operator: string,
Status: FlightStatus,
// ...
}
For every type of message you'd specify a handler that is able to handle a payload of a certain type. Note that these payloads have different types. Can we make this type-safe? And if so, how?
We ended up combining some advanced TypeScript features to do just that.
The solution
In order to guarantee type-safety over the streams we consumed we introduced a new type in our system, the StreamDefinition. This type represents what a stream means to our system, namely: a topic name, and an object that specifies which type of payload to expect for a given message type.
The base stream definition looks like:
interface StreamDefinition {
topic: Topic,
messages: {}
}
This basic interface could now be extended to create our stream interfaces:
interface FlightStream extends StreamDefinition {
topic: Topic.FlightInformation, // concrete value
messages: {
[MessageType.GateChange]: GateChange,
[MessageType.FlightUpdate]: FlightInformation,
}
}
Consumers of a stream have a handler function for every type of message. These handlers are provided as an object that maps the message type to the correct handler (example).
The following type was introduced to enforce this guarantee:
type StreamHandlers<Stream extends StreamDefinition> = {
[K in keyof Stream['messages']]: (payload: Stream['messages'][K]) => Promise<void>
};
This interface loops over all the keys of the messages property from the stream definition. It uses the keyof operator which was added in TypeScript 2.1. More specifically, this type of an interface is called a mapped type, because it maps over another type to create a new one.
While this type definition itself is not the most pretty thing in the world, it is very useful! It makes the following types equal:
type FlightStreamHandlers = StreamHandlers<FlightStream>;
// is the same as
interface FlightStreamHandlers = {
[MessageType.GateChange]: (message: GateChange ) => Promise<void>,
[MessageType.FlightUpdate]: (message: FlightInformation) => Promise<void>,
}
So instead of having a separate definition of the handlers, which could get out of sync, we use a mapped type. We can now use this interface for our handler objects:
const handlers: StreamHandlers<FlightStream> = {
[MessageType.GateChange]: async (message: GateChange) => {
// handle message
},
[MessageType.FlightUpdate]: async (message: FlightInformation) => {
// handle message
},
}
All we need now is a way to ensure the topic belongs to the stream, and we're off:
type topicForStream<Stream extends StreamDefinition> = Stream['topic'];
We can now combine these two interfaces to create our main interface, the Consumer interface:
interface Consumer<Stream extends StreamDefinition> {
consume(
topic: topicForStream<Stream>,
handlers: StreamHandlers<Stream>
): Promise<void>
}
In our application we used this interface tell our Kafka consumer which topic to read from and what type of payload to handle. By representing the streams as these definitions we were able to make our system a lot easier to understand.
Our stream definitions became first-class citizens within our application. Concepts that were previously loosely coupled are now combined into cohesive structures. The definitions encapsulates how every member in our team communicates and thinks about our streams.
But wait, there's more!
Consuming is only one side of stream processing. We also made it possible to ensure the correct MessageType and payload pairs were given when producing new messages.
For this we used the following interface:
interface Producer<Stream extends StreamDefinition> {
send<Type extends keyof Stream['messages']>(type: Type, payload: Stream['messages'][Type]);
}
This interface also uses the keyof operator. In this case we used it in the generic section of the method signature. This allows us to re-use the dynamic type reference in the parameters, which we use to link the concrete message type to the correct payload.
Here's an example of what that translates to when trying to use the wrong type (in a JetBrains IDE).
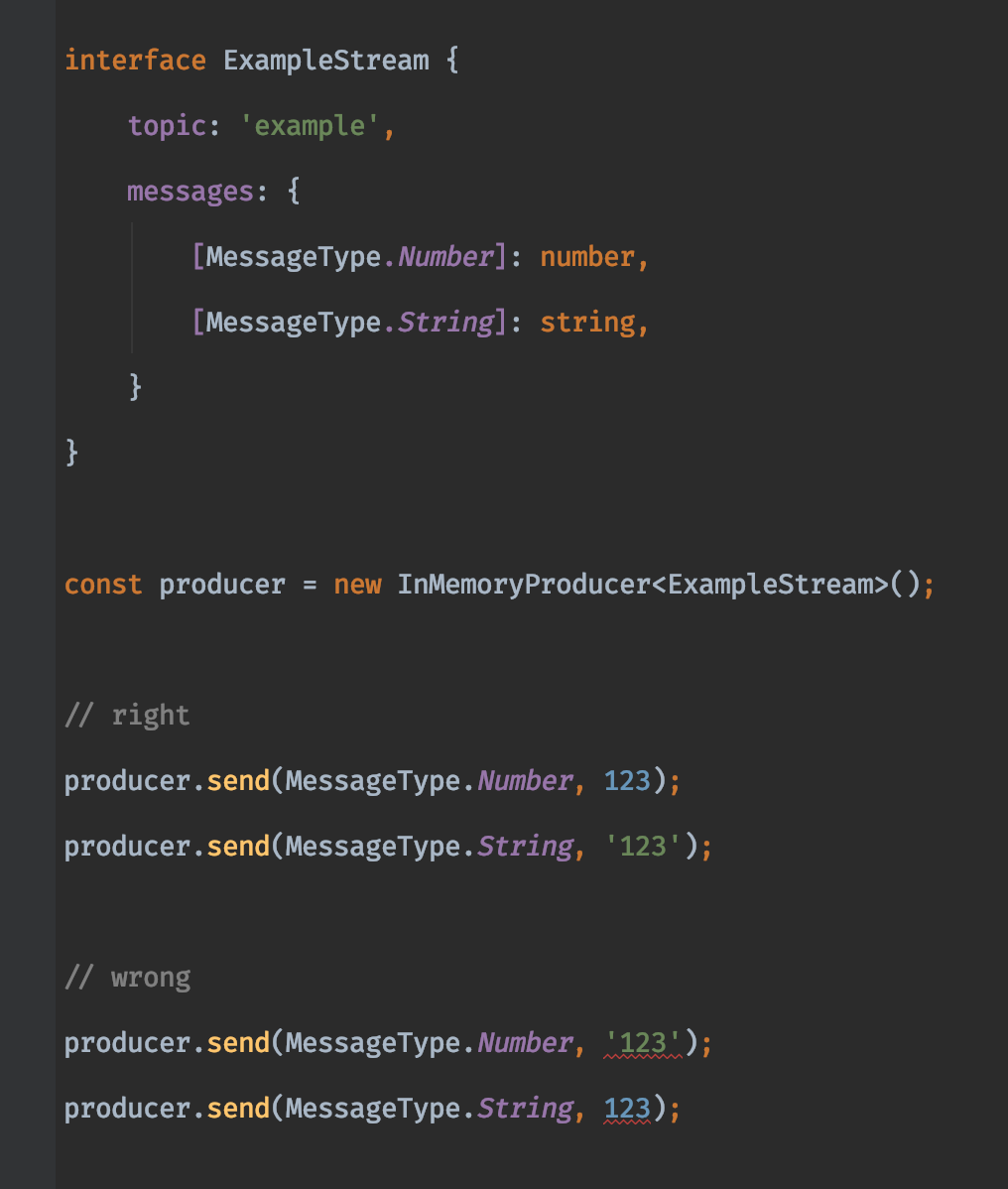
As you can see here, based on the message type (first) the corresponding payload type (second) is found and used to validate the input value.
Conclusion
Using TypeScript can give you very advanced type guarantees. Using interfaces and mapped types you can create a type-system for your stream-processing application.
This setup gave me and the other members of the team a lot of insight in how our application was setup and how the data was flowing through the system. Perhaps it can do the same for you!
For comments, visit reddit.