Partitioning for concurrency in synchronous business processes.
The PHP landscape is getting more and more diverse. The typical PHP + MySQL combination is no longer the only way of doing things. Applications in PHP are not just fancy database wrappers anymore. The solutions we build today do far more than just model the solution-space around storing records in databases. We use queueing systems, background processing, alternative storage solutions, and sometimes message or event-driven architectures. Aside from having to learn about those technologies, there's more than meets the eye.
![]()
New solutions create new problems.
With new ways of dealing with problems, new problems emerge. When the solution space evolves, so do the problems we deal with. One could say we only exchange one type of problem with another.
Exchanging one solution for another usually means you’re trading one problem for another. Storing records in a database is straightforward and simple, but it’s not a great way to notify other parts of your system something has happened. Queueing systems, on the other hand, are great at this. They open up a whole new set of possibilities.
Concurrent processing.
Message-driven architectures bring many new advantages such as faster initial responses, retry mechanisms, and easier integration with external systems. However, they also bring along lots of complexity. It's not just deployment routines that become more complex either. More often than not, the higher the gains, the more software needs to account for some of the added complexity.
Sequential processing constraints.
While matters like parallel processing are often associated with technical constraints, business constraints can also limit the technical possibilities. A business process may consist of multiple step that need to happen one after the other (synchronously). If we use parallel processing, we could run into race conditions.
Such constraints might steer you towards a synchronous solution, but a deeper understanding of a given domain might allow for an alternative approach. The need for synchronous processing is not always as final as it may seem. Sequential handling may only be a requirement within a certain context. A context may be defined by anything related to a single user, group, or even a process.
Such contexts can be used for logical grouping, which can allow for parallelism as long as we respect the business rules that dictate synchronicity.

It allows us to change from processing one stream of information containing multiple contexts...

... into multiple streams that can be processed synchronously.
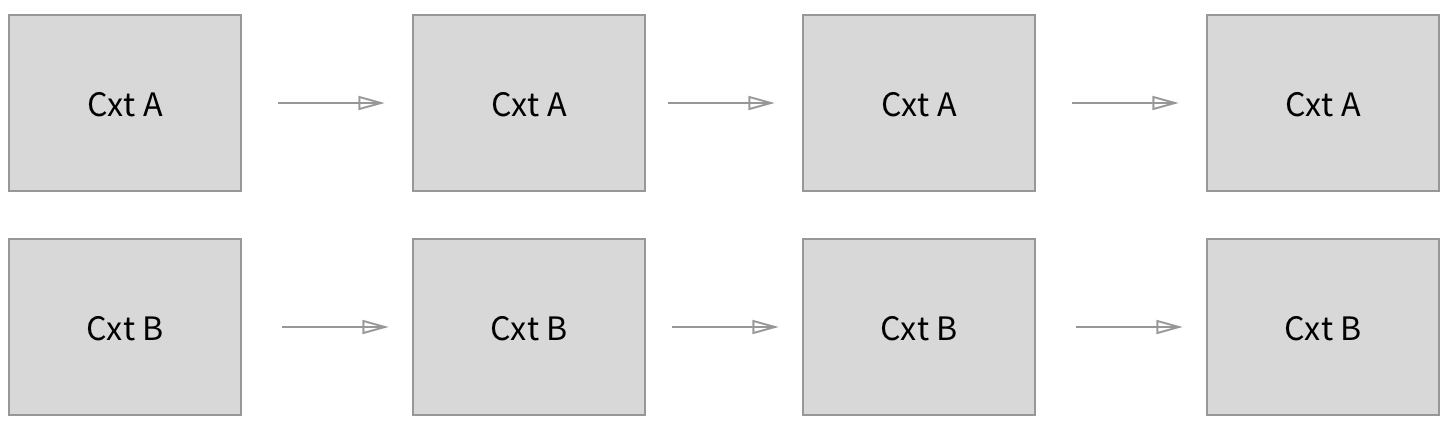
While individual streams can be processed in order, concurrency can be achieved between the streams.

Silly chat application.
Theory is nice, but examples are better. In this following example we'll create a chat application. The only business rule for this application is the following:
Every user must receive all messages in their mailbox in order.
All the messages will run through a queueing system to allow for background processing and async (or parallel) handling.

The image above illustrates the process for one user viewing the chat application. The messages sent through the system follow the arrows drawn between the blocks, representing the components of the system.
A more technical representation of the same architecture would be:
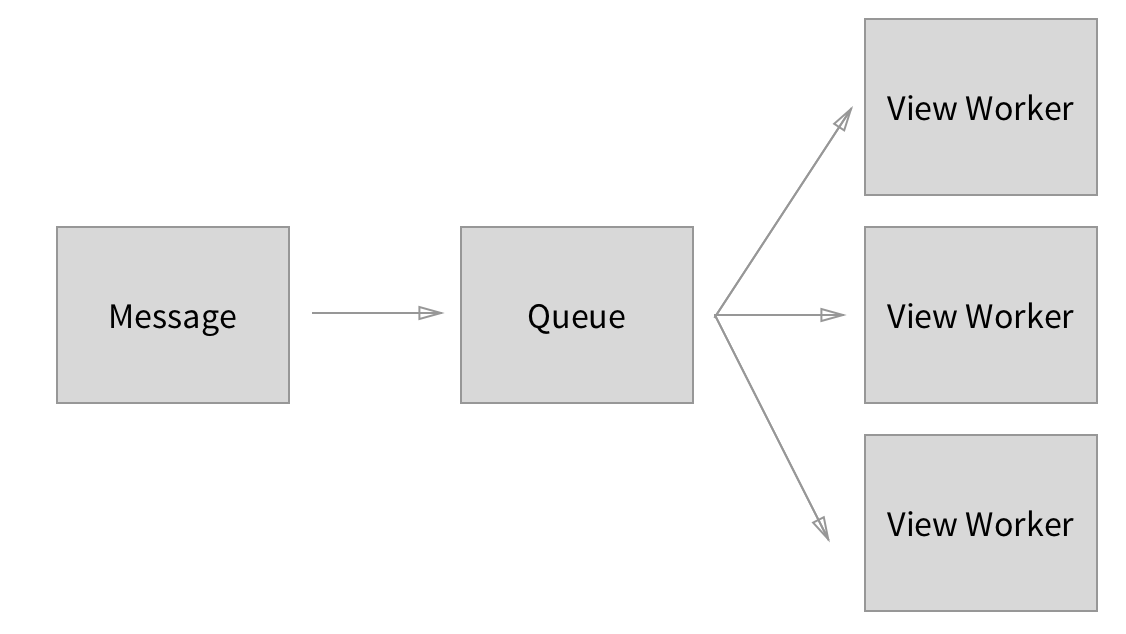
Here we can see that we have a message, which is passed through a queueing mechanism and sent to multiple workers.
The use of multiple workers allows for much higher throughput, but it also allows for race conditions during processing. When messages for the same user are sent to different workers, handling order can no longer be guaranteed. Therefore we have failed to fulfil our business rule.
If we were able to ensure every message from the same user were sent to the same worker, the worker could ensure those messages are handled in order while the system as a whole would still benefit from the degree of parallelism. But how do we make this happen? We can't simply spin up a new worker for every user of the system (although we're sprinting towards a future where that's actually possible/common and some languages already allow this today 😱).
Our lord and saviour: Partitioning!
Partitioning, in a general sense, is the process of dividing a large group into smaller groups. How these groups are formed varies based on your requirements.
Partitioning is often used for performance reasons. Partitioning itself takes a little bit of effort, but the gains are much higher. For example, indices are database partitions that allow for quick lookups. Writing to a database that has indices takes a little longer, but reading goes much faster. Some databases (such as ElasticSearch) also use partitioning to split data across nodes so they can hold more data collectively than possible on a single node.
Partitioning userland data in PHP
Partitioning, in its essence, is a classification/discrimination process. The goal of the partitioning process is not to uniquely identify items in a stream, but rather to ensure items that should be grouped together will be placed together.
When we partition items we use all the data that represents whatever makes a group unique. In our case, this could be the UUID of a user. This could also be a combination of multiple fields, as long as we can create a hash-based representation of said data. This hash should be unique for everything that needs to be handled in order. In our case this hash would be the same for every message going to the same user. Such an identifier can also be represented as an integer. Integers can be grouped together using the modulo operator. In pseudo-code this would look like:
partition = int_hash(input) % number_of_workers
This algorithm will make sure that input with an unknown number of synchronous streams will be divided over a known number of stream processors (workers) to allow for higher throughput due to increased parallelism.
...
Let's break that down. Partitioning is the process of grouping data that belongs together. This process uses data that makes the group unique. This grouping can be used to guarantee synchronous handling of processes. Partitioning algorithms as described above can handle an unknown number of groups, so you don't have to pre-assign groups. The individual groups can safely be processed in parallel which boosts the throughput of the system as a whole.
This particular type of partitioning is commonly known as “sharding”. Partitions created through sharding are referred to as “shards”. Each shard is a horizontal partition of the entire data collection. A horizontal partition means the partition holds all the related data, meaning we don’t have to look up information in other shards while processing.
The PHP implementation
class MessageForUser
{
public $recipientId; // UUID string
public $message; // text messsage
}
function partition(string $input, int $numberOfPartitions): int {
return abs(crc32($input)) % $numberOfPartitions;
}
$partition = partition($message->recipientId, 10);
This implementation uses the crc32 hashing function (standard library) to create a numeric hash. This function can return negative integers, so we use the abs function to ensure we have a positive number. Using the modulo operator we calculate the remainder. This number will be used to determine which topic/queue a message needs to be published on.
If you're using Apache Kafka, this number represents the actual partition. In other queueing systems you may need to map this number to a topic of some sort. If you’re using AWS SQS, the FIFO queue’s support MessageGroups which allows you to do the same thing.
On the consuming side of your system you now have to ensure only one worker is assigned to consume messages from a given partition. Having a single worker on a partition ensures the stream will be processed sequentially. The number of partitions don't have to match the number of workers, but a single partition can at most be handled by one worker.
Future problems.
By now we've made it possible to concurrently process multiple streams which are each handled sequentially. However, like I said before, rather than solving problems we've simply traded problems.
In this example we've used a fixed number of workers. In many cases this is enough, but it's good to keep in mind why and how we've used partitioning. This solution solved a problem, but if the need for parallelism grows, we'll have to reevaluate this solution.
We can't just add new workers and expect everything to keep working. The number of workers we distribute our work to relies on a consistent distribution. While creating the hash (integer) is consistent, calculating the remainder relies on the number of partitions. Adding a partition breaks this consistency. A message which would previously be assigned to partition 2 could now be assigned to 3. While this would affect processing only for a short while, the messages processed on the different partitions could effectively cause race conditions.
But don't worry, there's hope. There are techniques to mitigate the consistency breaks. Each with their own strengths and weaknesses. You could use the integer hash (which is consistent) and store/cache which partition was assigned to it. This way everything in the "old" situation would still be assigned to the same partition while new information can benefit from being distributed to the new worker. This approach works better for finite processes.
You can look into how long the distribution needs to be consistent or see if your system protects itself against race-conditions in other ways. Alternatively you could redistribute the messages across a higher number of partitions, this is a typical thing to do when using Kafka.
Another approach can be to always create more shards than workers. Remember that a single shard can only be processed by one worker, but one worker can process more than one shard. During normal system load each worker processes messages from multiple shards, but when the load increases we can simply add more workers and redistribute the shards.
Each of these mitigation strategies has their own up- and down-sides. Which one is right for you? That's for you to find out.
The DDD mindset can be very important.
All in all there are many considerations to be made when diving into the world of parallel processing. Some negative side-effects may not be apparent from the start. Some restrictions may only apply to a subset of the problem area. Sometimes when we solve one problem, more problems arise. Sometimes those problems affect you, sometimes they don't. It's your job as a developer to take those things into consideration.
The mindset of Domain Driven Design, especially having meaningful domain centric conversations with domain experts, can become very important. After all, it was a business rule that provided us the restriction of and the opportunity for parallel processing. Having a deep understanding of a domain allows you to have these insights, even at seemingly low level.
Résumé
A meme is worth a thousand words:
